- 맥북에서 PySpark 로컬 실행환경 설치를 해보기 위한 방법을 정리하였다. 데이터 엔지니어링을 공부하면 Spark는 꼭 다뤄야 하는 기술 중 하나이다.
- Jupyter Extension을 활용하여 Notebook 기반으로 실행하는 방식까지 확인해본다.
1. 기본 준비물 VSCode + Jupyter 환경 구성
VS Code 다운로드
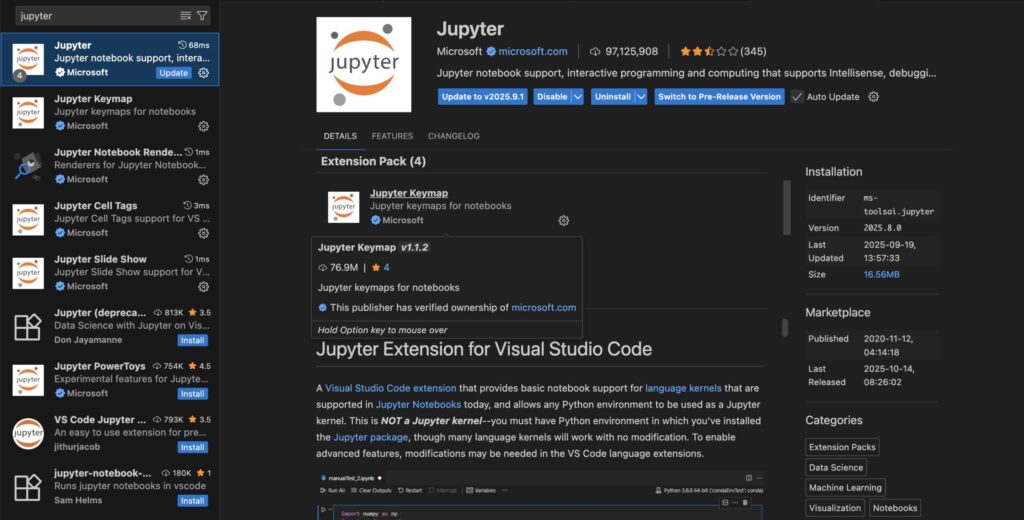
처음 설치는 기본 환경 준비를 위해 위에 링크를 들어가 VS Code 를 설치하고 위 화면과 같이 Extension 에서 Jupyter를 설치한다.
2. Homebrew 설치 여부 확인
!brew --version
!brew update-reset && brew update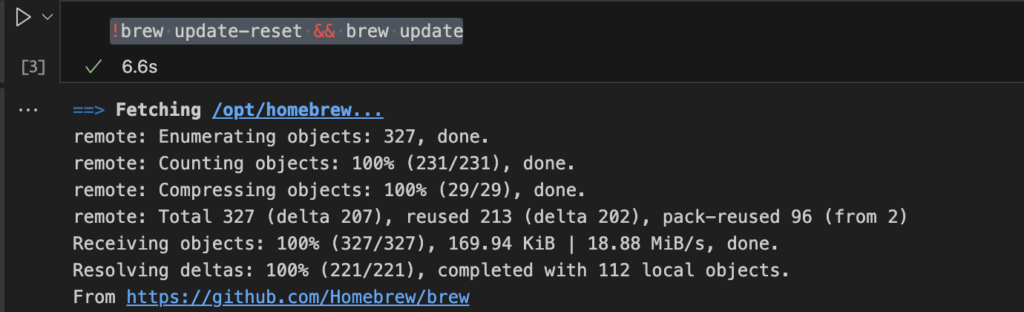
맥북에서는 pySpark를 설치하기 위해 Brew 패키지를 활용한다.
3. Open JDK 패키지 조회 및 설치
JDK 설치가 꽤 까다로울 수 있는데, Spark 버전과 호환되는 JDK 버전을 설치해야된다. 아니면 오류가 발생하기 때문에 Spark는 Java 기반이므로 OpenJDK 17 이상 설치를 추천한다.
!brew search openjdk@17
!brew install openjdk@17Path 설정
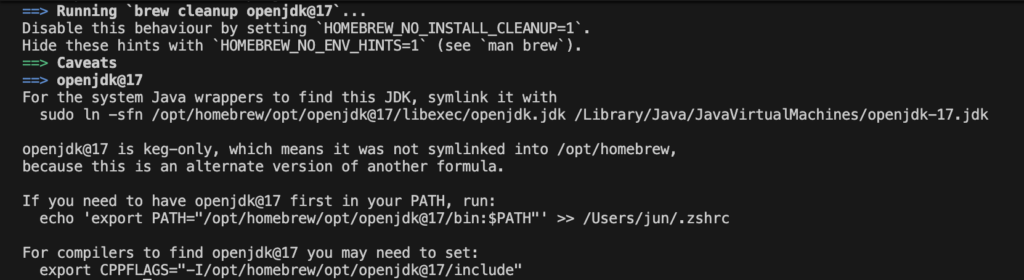
JDK 설치 이후 위에 Java 경로를 환경변수에 등록한다.
# 심볼릭 링크 생성
sudo ln -sfn /opt/homebrew/opt/openjdk@17/libexec/openjdk.jdk /Library/Java/JavaVirtualMachines/openjdk-17.jdk
# PATH 설정
echo 'export PATH="opt/homebrew/opt/openjdk@17/bin:$PATH"' >> /Users/{사용자명}/.zshrc
# java 버전
java -version
4. Apache Spark 설치
드디어 pySpark 를 설치해본다. Notebook에서 설치하는 방법이다.
!pip install findspark pyspark # 현재 기준 version 4.0.1으로 설치됨
# 또한 brew를 활용하여 설치가 가능함.
brew install apache-sparkimport os
os.environ["JAVA_HOME"] = "/opt/homebrew/opt/openjdk@17"
import findspark
findspark.init()
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("Hello PySpark").getOrCreate()
df = spark.range(0,10)
df.show()
위에 코드까지 수행이 되면 Spark를 로컬에서 시작할 준비가 되었다.
이후 간단히 spark로 DataFrame을 만들어보자.
